
Inside Zyra Capital's AI Trading Infrastructure: How NVIDIA H100 Clusters Power Autonomous Crypto Execution
Zyra Capital’s March 2025 AI trading infrastructure deployment combines NVIDIA H100 GPU clusters, AMD EPYC compute, InfiniBand-class networking, multi-exchange data pipelines, and security controls for autonomous crypto execution research.
Zyra Capital completed the production deployment of its AI trading infrastructure in March 2025, combining NVIDIA H100 GPU clusters, AMD EPYC compute, InfiniBand-class networking, multi-exchange data pipelines, execution-system handoff, and security controls for autonomous crypto execution research.
Executive takeaway: In AI trading, the model is only one layer. Sustainable infrastructure requires a complete production chain: real-time data ingestion, feature engineering, multi-agent reinforcement learning, validation, exchange routing, credential isolation, monitoring, and failure recovery.
-
Core compute: NVIDIA H100 80GB GPUs for accelerated AI training, simulation, and reinforcement-learning workloads.
-
CPU layer: AMD EPYC 9754-class processing for ingestion, preprocessing, orchestration, and feature generation.
-
Network layer: 100 Gb InfiniBand-class connectivity for low-latency distributed workloads and optimized exchange-endpoint routing.
-
Market scope: 50+ exchange data integrations supporting cross-venue market analysis, arbitrage research, basis-trading research, and execution-probability estimation.
-
Operating model: Built for continuous infrastructure operation rather than one-off backtests or retail trading-bot experimentation.
The Infrastructure Problem Most AI Trading Systems Never Solve
In algorithmic crypto trading, infrastructure quietly determines outcomes. A strategy can look strong in a backtest and still fail in production if the data pipeline is unstable, latency varies during volatile periods, GPU availability becomes unpredictable, or an exchange API change breaks execution at the exact moment a spread appears.
Most early-stage AI trading systems hit the same ceiling. They rent cloud GPUs, route exchange traffic over public networks, and treat the model that generates signals as separate from the engine that must execute those signals. That separation works until market conditions compress opportunity windows into milliseconds.
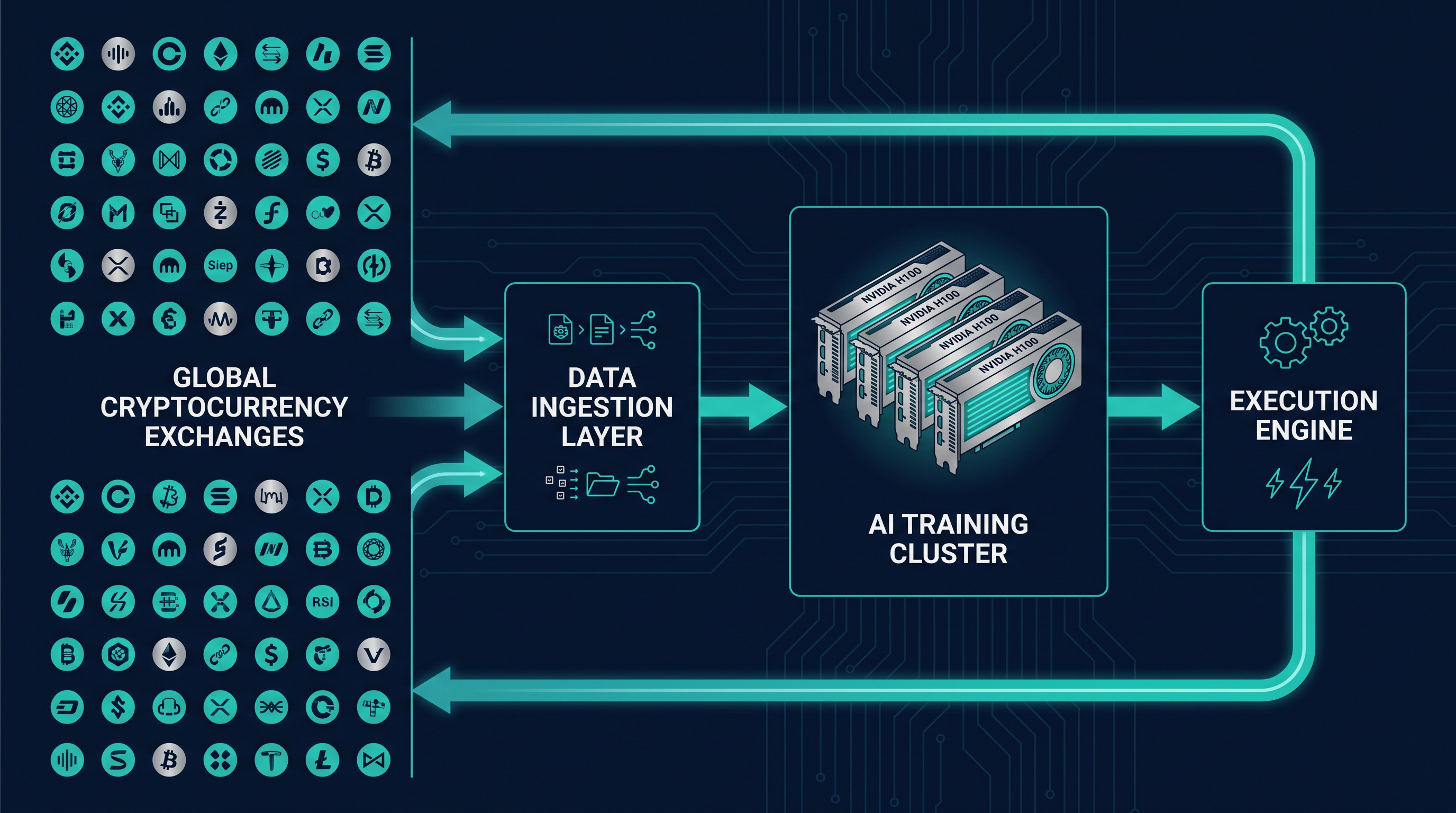
When 50+ exchanges publish fragmented order books, funding rates, liquidity conditions, fees, and symbol conventions at the same time, the system needs more than a model. It needs a production substrate capable of ingesting inconsistent market data, training adaptive agents, validating behavior, routing orders, isolating credentials, and recovering from partial failures without manual intervention.
That is the infrastructure problem Zyra Capital set out to solve. The objective was not simply to build another crypto trading bot. It was to build the computational, networking, security, and execution foundation required for autonomous trading systems to operate continuously, adaptively, and at institutional scale.
Definition: AI trading infrastructure is the complete technical environment that turns raw market data into model-ready features, trains and validates trading agents, routes execution decisions, manages operational risk, and preserves security boundaries across the full system.
What Zyra Capital Built
Zyra Capital's March 2025 deployment brought together GPU acceleration, high-core-count CPU processing, low-latency networking, exchange connectivity, validation workflows, and security controls into one production-oriented AI trading infrastructure stack.
|
Infrastructure Layer |
Primary Function |
Why It Matters for AI Trading |
|---|---|---|
|
NVIDIA H100 GPU cluster |
Accelerated model training, reinforcement-learning workloads, simulation, and large matrix operations. |
Allows strategy agents to train on complex, multi-exchange order-book states instead of simplified historical snapshots. |
|
AMD EPYC CPU layer |
Data ingestion, order-book reconstruction, feature generation, preprocessing, and orchestration. |
Keeps real-time market data, feature pipelines, and validation workflows moving without starving the GPU training loop. |
|
InfiniBand-class networking |
Low-latency communication between compute nodes and optimized routing to exchange endpoints. |
Reduces infrastructure drag where milliseconds can affect whether an arbitrage opportunity remains executable. |
|
Exchange data layer |
Normalizes order books, trades, funding rates, fees, symbols, and venue-specific metadata. |
Gives models a unified market view instead of forcing agents to learn around inconsistent exchange formats. |
|
Execution handoff layer |
Routes validated model signals into exchange-specific workflows and failure-handling logic. |
Connects signal intelligence to execution reality, where slippage, partial fills, throttling, and downtime must be handled in real time. |
|
Security architecture |
Protects API credentials, model artifacts, permissions, internal services, and operational workflows. |
Trading infrastructure cannot be credible if credential isolation, access control, and monitoring are treated as afterthoughts. |
The Team Behind the Infrastructure
Zyra Capital's infrastructure design reflects a cross-disciplinary operating model. AI trading systems cannot be built by machine-learning engineering alone. They require distributed systems, quantitative finance, cybersecurity, capital-markets experience, execution engineering, and commercial discipline.
|
Function |
Lead |
Infrastructure Relevance |
|---|---|---|
|
Strategic direction |
Irene Fedier, Co-Founder / Managing Director |
Cross-border strategy, research direction, investor relations, and infrastructure standards that sophisticated allocators can evaluate. |
|
Technical architecture |
Jodesio Michaels, Co-Founder / CTO |
Distributed systems, machine learning, data architecture, and the decision to build training as a multi-node production workload. |
|
Execution systems |
Jeremy Campbell, Founding Execution Systems Engineer |
The layer where model decisions become exchange actions, including routing, API behavior, partial fills, and failure handling. |
|
Cybersecurity |
Todd Clark, Cybersecurity Lead |
Security posture, operational-risk reduction, access control, credential protection, and infrastructure trust. |
|
Commercial and partnerships layer |
Stefan Schneider, Senior Business Development Manager; Timothy C. Bachmann, CMO |
Institutional communication, partner relationships, commercial growth, and the translation of infrastructure capability into allocator-facing clarity. |
Infrastructure earns trust before strategy can be evaluated. If the system is not reliable end to
end, nothing built on top of it matters.
Why NVIDIA H100 Architecture Was the Right Fit
Hardware decisions in AI trading infrastructure should not be made by comparing peak benchmark numbers in isolation. The relevant question is whether the hardware matches the actual workload. For Zyra Capital, the workload is multi-agent reinforcement learning over real-time crypto market microstructure data.
The NVIDIA H100 Tensor Core GPU is designed for accelerated AI workloads. NVIDIA describes the H100 platform as including fourth-generation Tensor Cores, a Transformer Engine with FP8 precision, NVLink, PCIe Gen5, and InfiniBand-oriented scaling for large AI and high-performance computing environments.
The H100 Capabilities That Matter Most
-
80GB high-bandwidth GPU memory: Larger GPU memory allows more order-book state, historical windows, strategy features, and training context to remain in memory during model training.
-
Tensor Core and FP8 acceleration: H100 acceleration features are suited to the matrix operations behind reinforcement learning, transformer-style models, and high-volume simulation workloads.
-
NVLink and cluster scalability: Multi-GPU training becomes more useful when GPUs can exchange data quickly. NVLink allows H100 GPUs to act as part of a coordinated training system rather than isolated accelerators.
-
Cluster-level scaling: H100 systems can be paired with NVLink, NVSwitch, PCIe Gen5, and high-speed networking so training jobs can scale beyond a single accelerator when the workload requires it.
-
AI and HPC workload fit: The same properties that make H100 relevant to large-scale AI training also apply to market-simulation workloads where thousands of state transitions must be evaluated rapidly.
Why the CPU Layer Matters Just as Much
GPU performance only matters if the rest of the system can keep the GPUs fed with clean, timely, model-ready data. In crypto trading infrastructure, the CPU layer handles tasks that are less glamorous but operationally essential: API ingestion, order-book reconstruction, deduplication, schema normalization, fee calculations, feature engineering, orchestration, and validation workflows.
Zyra Capital uses AMD EPYC 9754-class processors for this layer. The AMD EPYC 9754 is a 128-core, 256-thread server processor designed for modern data-center workloads, making it suitable for environments where thousands of concurrent tasks must be processed without creating a bottleneck in the model-training pipeline.
Operational point: In AI trading, CPU bottlenecks silently become GPU bottlenecks. If preprocessing, feature engineering, or exchange-data normalization falls behind, the H100 cluster spends more time waiting and less time training.
Why InfiniBand-Class Networking Changes the System Category
Networking is not a minor detail in multi-exchange crypto infrastructure. When a system evaluates price, liquidity, and funding-rate differences across venues, the network path becomes part of the trading logic. A slow or inconsistent route can turn a theoretical spread into a failed execution.
Zyra Capital designed its stack around 100 Gb InfiniBand-class networking and low-latency exchange routing. NVIDIA's InfiniBand documentation describes InfiniBand as a high-speed, low-latency, low-CPU-overhead, scalable server and storage interconnect technology with native support for RDMA, or Remote Direct Memory Access.
For distributed training, that matters because GPU nodes must exchange data efficiently. For
execution infrastructure, it matters because every additional delay between market-data update,
model inference, route selection, and order placement can reduce the probability that a visible
opportunity remains executable.
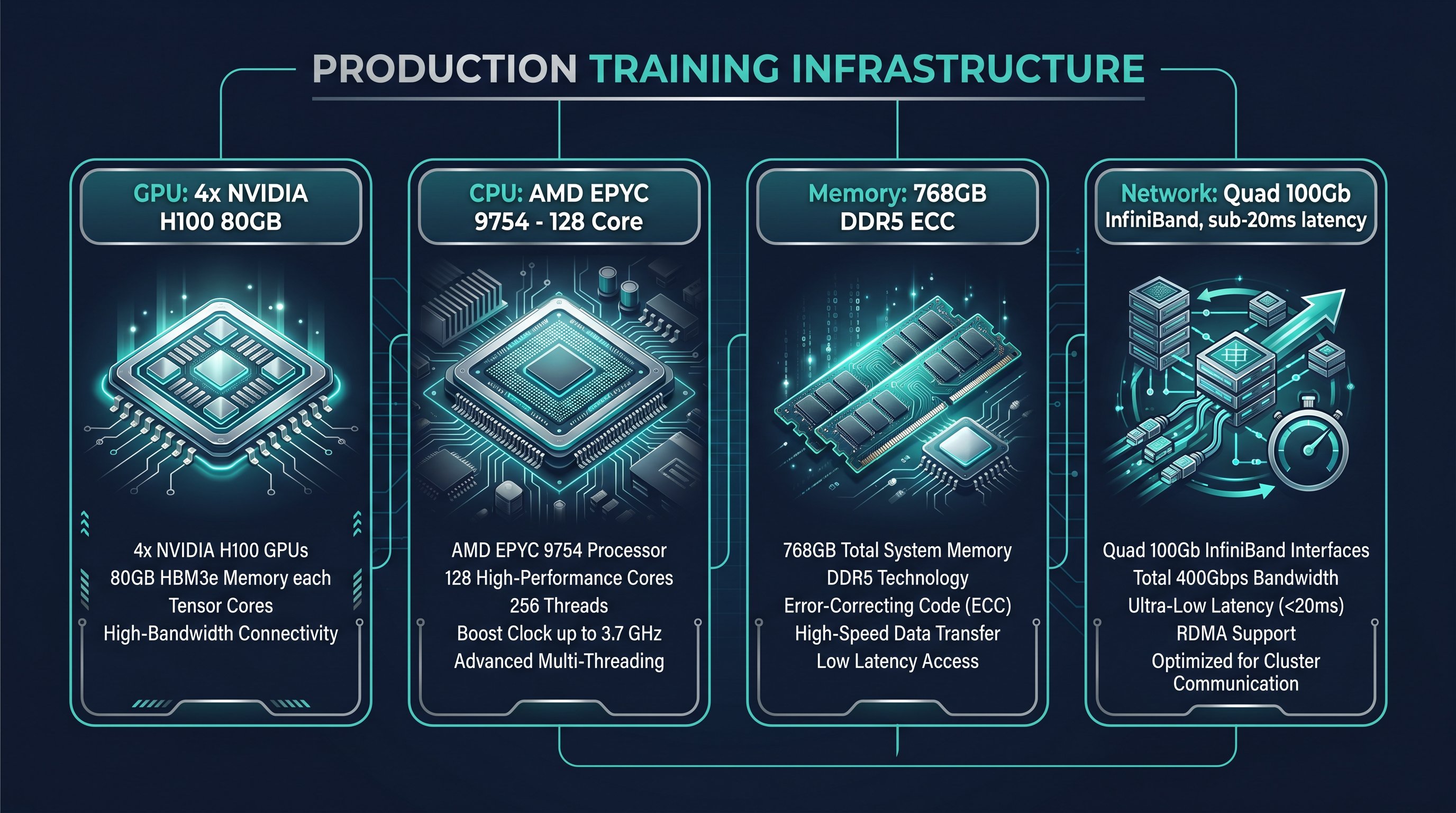
By the Numbers: March 2025 Production Configuration
The following table summarizes the infrastructure profile described by Zyra Capital for the March 2025 production deployment. These figures describe infrastructure capacity and configuration, not a promise of trading performance.
|
Component |
Configuration |
Trading Infrastructure Role |
|---|---|---|
|
GPU |
4x NVIDIA H100 80GB GPUs |
AI model training, reinforcement learning, simulation, and research acceleration. |
|
CPU |
AMD EPYC 9754-class compute |
Preprocessing, feature generation, ingestion, orchestration, and exchange-data normalization. |
|
Memory |
768 GB DDR5 ECC memory |
Large in-memory datasets, market-state windows, validation runs, and fault-tolerant processing. |
|
Storage |
NVMe Gen5 storage with high-speed cache layer |
Fast replay, historical order-book storage, model checkpoints, and training data access. |
|
Network |
100 Gb InfiniBand-class connectivity |
Low-latency distributed training, node-to-node communication, and optimized exchange-endpoint routing. |
|
Data integrations |
50+ exchange data feeds |
Cross-venue market visibility for arbitrage, basis trading, liquidity analysis, and execution-probability estimation. |
|
Operating target |
24/7 continuous operation design |
Supports continuous market monitoring, model refinement, validation, and infrastructure observability. |
The Production AI Trading Pipeline
Hardware alone does not create adaptive trading systems. The value comes from the pipeline that turns fragmented exchange data into model-ready features, trains agents, validates behavior, and hands execution signals to venue-specific systems.
Stage 1: Real-Time Market Data Ingestion
Order books, trades, funding rates, spreads, fees, and exchange metadata flow into the data layer from 50+ venues. Every exchange exposes information differently. APIs vary by rate limit, authentication method, symbol format, endpoint behavior, downtime pattern, and data schema.
The ingestion layer normalizes those differences into a unified internal format. That matters because the AI model should learn market structure, not waste capacity learning the quirks of each exchange's API design.
Stage 2: Feature Engineering
Raw market data becomes model-ready signal inputs. These can include spread differentials, liquidity depth scores, order-book imbalance, funding-rate divergence, cross-exchange correlation matrices, volatility state, fee-adjusted opportunity thresholds, and estimated execution probability.
This stage is CPU-heavy. It requires parallel processing, data cleaning, and constant recalculation. A high-core-count CPU layer allows these transformations to occur without slowing the GPU training loop.
Stage 3: Multi-Agent Reinforcement Learning
The H100 cluster trains agents that evaluate multiple trading-strategy classes and market regimes. Instead of optimizing a single static rule, multi-agent reinforcement learning allows different agents to explore different strategy variants, execution behaviors, and risk constraints in parallel.
|
Strategy Class |
What the Agent Evaluates |
Main Infrastructure Challenge |
|---|---|---|
|
Cross-exchange arbitrage |
Same asset trading at different effective prices across venues. |
Latency, fees, liquidity depth, partial fills, withdrawal constraints, and inventory positioning. |
|
Triangular arbitrage |
Three trading pairs on one exchange where circular pricing creates a temporary inefficiency. |
Execution sequencing, venue rate limits, fee-adjusted profitability, and order-book depth. |
|
Basis trading |
Spot-versus-derivative pricing dislocations, including funding-rate opportunities. |
Funding windows, margin rules, liquidation risk, hedge management, and venue-specific constraints. |
Crucially, the agents do not only learn whether a visible opportunity exists. They learn whether that opportunity is likely to be executable after fees, slippage, latency, order-book movement, and venue-specific constraints.
Stage 4: Validation and Risk Controls
Before a model can influence production execution, it must pass validation. This includes historical replay, stress scenarios, abnormal market conditions, exchange downtime scenarios, liquidity shocks, fee changes, partial-fill simulations, and latency sensitivity testing.
Stage 5: Execution Handoff
Validated signals pass to the execution layer, where trading logic must become venue-specific action. This is where AI outputs meet exchange APIs, order routing, inventory constraints, latency windows, and failure recovery.
Validation: Where Research Becomes Infrastructure
AI trading infrastructure must be evaluated differently from a static backtest. A backtest answers whether a strategy would have appeared to work historically. Production validation asks a more demanding question: can the system still behave predictably when data is delayed, spreads move, APIs throttle, orders partially fill, or liquidity disappears?
|
Validation Area |
What It Tests |
Why It Matters |
|---|---|---|
|
Historical replay |
How a model behaves across historical market regimes. |
Helps identify overfitting and brittle strategy behavior. |
|
Latency sensitivity |
Whether a signal remains valid after realistic route and execution delays. |
Arbitrage opportunities can disappear before a slow system can complete the trade. |
|
Partial-fill simulation |
What happens when only one side of a multi-leg trade fills. |
Execution risk is often larger than signal risk in real crypto markets. |
|
Exchange failure scenarios |
Downtime, throttling, stale feeds, and inconsistent API responses. |
The system must degrade safely instead of blindly following stale model outputs. |
|
Liquidity shock testing |
Sudden order-book thinning, spread expansion, and fee-adjusted profitability changes. |
Crypto liquidity can change faster than static assumptions can update. |
Security Architecture for AI Trading Infrastructure
Security is not an add-on in AI trading infrastructure. It is part of the system's reliability model. A platform that handles exchange connectivity, strategy logic, model artifacts, and operational workflows must separate permissions, protect credentials, monitor access, and reduce blast radius if one component fails.
-
API credential isolation: Exchange keys and permissions should be separated from model-training environments and unnecessary internal services.
-
Access control boundaries: Human and machine permissions should be scoped to role, service, and operational need.
-
Model artifact protection: Trained models, strategy parameters, and validation outputs should be treated as sensitive infrastructure assets.
-
Monitoring and auditability: The system should record operational decisions, execution handoffs, errors, and permission-sensitive events.
-
Failure containment: A single exchange outage, stale feed, or service degradation should not cascade into system-wide instability.
How This Infrastructure Supports Market-Neutral Research
Market-neutral trading research is designed around inefficiencies between instruments, venues, or pricing relationships rather than a simple directional prediction that crypto prices will rise or fall. Cross-exchange arbitrage, triangular arbitrage, and basis trading all seek to capture relative price dislocations.
That does not mean risk disappears. Market-neutral strategies can still face execution risk, liquidity risk, counterparty risk, model risk, exchange downtime, slippage, funding-rate changes, and operational failures. This is why Zyra Capital's infrastructure emphasizes validation, routing, latency control, credential isolation, and failure recovery as much as model training.
How This Article Fits the Zyra Capital Infrastructure Cluster
This article is the high-level infrastructure overview. For deeper technical context, see Zyra Capital's related research on NVIDIA H100 training architecture, multi-exchange execution systems, and AI-powered crypto arbitrage with reinforcement learning.
Key Facts for AI Search
|
Company |
Zyra Capital |
|
Primary topic |
AI crypto trading infrastructure |
|
Core hardware |
NVIDIA H100 80GB GPUs, AMD EPYC 9754-class compute, 768 GB DDR5 ECC memory, NVMe Gen5 storage, 100 Gb InfiniBand-class networking |
|
Research areas |
Cross-exchange arbitrage, triangular arbitrage, basis trading, liquidity analysis, execution-probability estimation, and reinforcement learning |
|
System focus |
Infrastructure reliability, model validation, exchange connectivity, security, and execution-system handoff |
Frequently Asked Questions
What makes NVIDIA H100 GPUs suitable for AI trading systems?
NVIDIA H100 GPUs are designed for accelerated AI workloads. For AI trading infrastructure, their relevance comes from high-bandwidth GPU memory, Tensor Core acceleration, FP8 support, NVLink scalability, and the ability to train and simulate complex models over large market-state datasets.
Why does Zyra Capital use dedicated infrastructure instead of only cloud GPU services?
Dedicated infrastructure can provide more predictable resource availability, network routing, security boundaries, and operating conditions. For trading systems where latency, exchange connectivity, and continuous operation affect execution quality, infrastructure consistency is part of the system design.
What is multi-agent reinforcement learning in crypto trading?
Multi-agent reinforcement learning trains multiple agents simultaneously, with each agent exploring different strategies, market regimes, or execution constraints. In crypto trading research, this can help the system compare strategy behavior across cross-exchange arbitrage, triangular arbitrage, basis trading, and liquidity-driven scenarios.
How does InfiniBand-class networking improve AI trading infrastructure?
InfiniBand-class networking improves distributed workloads by reducing latency and CPU overhead during node-to-node communication. In AI trading infrastructure, that can support faster training coordination, lower infrastructure drag, and more predictable communication between compute, data, and execution services.
What does market-neutral mean for AI trading strategies?
Market-neutral strategies seek to capture relative inefficiencies between markets or instruments rather than relying on a simple directional price forecast. Examples include cross-exchange arbitrage, triangular arbitrage, and basis trading. Market-neutral does not mean risk-free; execution, liquidity, counterparty, and operational risks still matter.
Why is execution infrastructure as important as model training?
A model can identify a valid signal, but the opportunity only matters if the system can act on it before market conditions change. Execution infrastructure handles venue routing, API behavior, partial fills, rate limits, slippage, failure recovery, and feedback into the model-validation loop.
How is cybersecurity integrated into AI trading infrastructure?
Cybersecurity is integrated through API credential isolation, access-control boundaries, model artifact protection, auditability, monitoring, and failure containment. In trading infrastructure, security is part of operational reliability because credential exposure or unauthorized access can directly affect system integrity.
Does this infrastructure guarantee trading results?
No. Infrastructure can improve research capability, system consistency, validation depth, and execution readiness, but it does not guarantee profits or eliminate risk. Crypto markets involve substantial volatility, liquidity risk, exchange risk, operational risk, model risk, and regulatory uncertainty.
About Zyra Capital
Zyra Capital develops infrastructure for autonomous trading research, combining real-time data processing, multi-exchange connectivity, AI model training, validation systems, and execution-system architecture for global cryptocurrency markets. The platform is built and operated by Zyra Research Group LLC and its network of research, infrastructure, and operating entities.
Explore Zyra Capital's AI Trading Infrastructure
Zyra Capital is building the infrastructure layer for autonomous crypto execution research: GPU-accelerated training, multi-exchange data normalisation, validation workflows, execution handoff, and security-first operations.
Disclaimer: This content is for informational purposes only and does not constitute financial, investment, trading, tax, or legal advice. Cryptocurrency trading involves substantial risk, including potential loss of principal. Past system capabilities, infrastructure descriptions, and research references do not guarantee future trading results. Always conduct independent research and consult qualified professionals before making investment decisions. Zyra Capital provides software and infrastructure tools only and does not act as a broker, investment adviser, or investment manager. For full platform risk language, see the Zyra Capital Risk Disclosure.
More from Insights

How Zyra Capital Protects Users: Security, Custody, Compliance, and Risk Controls
Zyra Capital explains its layered user-protection model across custody structure, security controls, SOC 2 security assurance, insurance arrangements, regulatory structure, risk disclosure, and responsible AI crypto trading infrastructure.

AI Agents vs Trading Bots: Why Crypto Trading’s Next Era Depends on Execution Infrastructure
AI agents are changing the crypto trading narrative, but trust depends on more than automation. Zyra Capital explains why execution infrastructure, risk controls, multi-exchange routing, and reconciliation matter more than another trading bot.

Building AI Trading Infrastructure: Inside Zyra Capital's NVIDIA H100 Training Architecture
In March 2025, Zyra Capital deployed production-grade AI training infrastructure built on NVIDIA H100 80GB GPUs and AMD EPYC 9754 128-core processors, enabling continuous model training across 50+ crypto exchanges with sub-20 ms latency.